Hot Topics in FAIR Data: An Orientation for the Uninitiated
“Data” has become a watchword in academic circles – not to mention in society writ large. But it can be difficult to stay abreast of data-related developments as a plethora of organizations, initiatives, and technologies emerge. I recently had the privilege of attending and speaking at a CODATA workshop on FAIR data (which I’ll explain momentarily) and responsible research data management. Hosted at Drexel University, the two-day workshop brought together self-proclaimed “data nerds” – including librarians, scientists, IT specialists, and publishers – from four continents. Below, I share three trends to watch in the FAIR data space. But first…
What is FAIR?
The FAIR data principles were established at a workshop in Leiden in 2014 and published in the journal Scientific Data. FAIR stands for Findable, Accessible, Interoperable, and Reusable data – for both humans and machines. FAIR proponents want both people and machine learning systems to easily be able to locate and use research data as much as possible while still maintaining necessary privacy protections. Ultimately, they envision a world in which computers can search for relevant information and query it to produce transformative research insights, with minimal human involvement.
It’s easy for the uninitiated to confuse FAIR with parallel movements in scientific practice and scholarly communications – much to the chagrin of hardcore FAIRers. “FAIR data is not sharing data, and it’s not open data,” one workshop attendee said emphatically. It is still possible for data to be FAIR even if access to it is highly restricted; for example, a team at the Children’s Hospital of Philadelphia is working to make patient data FAIR within the hospital’s own closed-access information system, enabling use by affiliated clinician-scientists.
Ontologies for Machine Readability
The technical jargon of the FAIR data community can be intimidating, but some of these abstruse concepts are essential to solving the complex problems in data protection and reuse. Take, for example, ontologies. An ontology is a logical system that shows the relationships between different concepts within a particular subject area. Here’s an example of a simple ontology featuring my cat:*
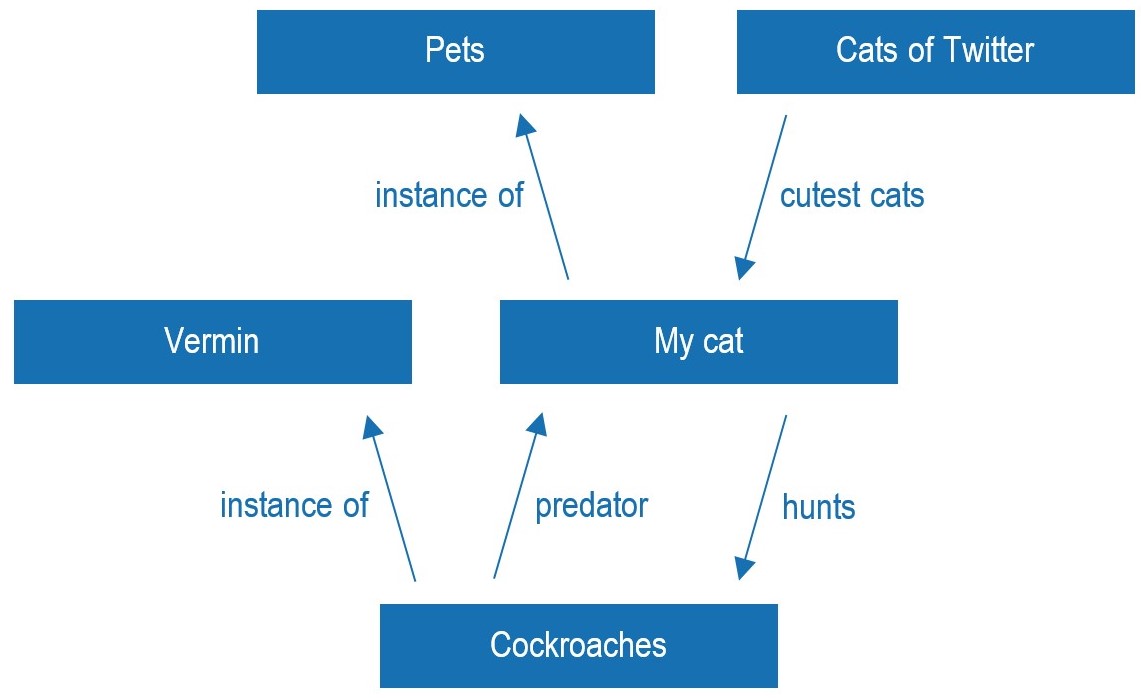
There are a number of ongoing projects that use ontologies to bring the goals of FAIR data within reach. Consider, for instance, the complexities of using patients’ health data for research. Before using this data, patients must sign an “informed consent” document that states that they understand and agree to the research being conducted. In an ideal FAIR world, a computer would be able to search a huge database of patient data, including digital copies of consent forms, and perform research queries on only data from patients who had consented to that particular type of research. The problem is that lawyers write consent forms to be comprehensible to people, not computers. A team of researchers at Drexel University is using machine learning and natural language processing to help computers decipher these documents using ontologies.
Google Takeover?
From Ithaka S+R’s research support services projects, we know that researchers often feel overwhelmed by the multiplication of available repositories for storing and finding data. Several existing data discovery platforms, including DataCite’s Repository Finder, Canada’s FRDR, and Australia’s RDA enable searching across many of these smaller platforms. Will these be superseded by Google’s Dataset Search in the future?
For the time being, there are limitations to Google’s service, which is still in beta. In order for Google’s crawlers to locate a dataset, it must be stored on a webpage that has metadata, a sitemap, and proper indexing. For data producers, an easy shortcut to meeting these requirements is to use DataCite DOIs. Integration with Google Scholar, Google’s widely-used bibliographic search, promises increased findability – a little-used, but important, argument in favor of developing standards for data citation.
The Personal Health Train
The most exciting technology I learned about at the CODATA workshop is something called the Personal Health Train (PHT), a novel solution to address issues of data privacy and community knowledge control. It works like this. When a researcher wants to analyze a dataset, she sends out a virtual machine (the “train”) which travels to the dataset (the “station”), performs whatever queries the researcher specified, then chugs along back to the researcher with only the results, not the data itself. There is no need to download entire datasets, and since the owner of the data can control exactly what type of research is allowed, the necessary privacy is easily preserved. Although the Personal Health Train was developed with medical data in mind, its use could easily be expanded to other domains. Widespread implementation of this technology is still a long way off, but it has the potential to transform data sharing into data visiting.
Final Thoughts
Besides comprising a fortunate acronym, the FAIR data principles provide forward-looking guidelines for progress toward an ambitious goal. One of the greatest challenges facing the FAIR community is how to consolidate the plethora of promising initiatives in this area – many with overlapping goals – in order to streamline efforts and, ultimately, achieve widespread buy-in from the academic community. The innovations highlighted above are just some of the promising avenues toward this goal.
*Inspired by: https://protege.stanford.edu/publications/ontology_development/ontology101-noy-mcguinness.html.