Data Communities in the Health Sciences
A Webinar with the Long Island Library Resources Council
Data sharing in the health sciences has never seemed more urgent. The National Institutes of Health, the US’s major health science research funder, has been experimenting with ways to promote data sharing. Additionally, the race to combat COVID-19 has brought the urgency of making patient-level clinical data, as well as other types of health-related data, easily accessible to researchers while still maintaining individual privacy. Against this backdrop, Danielle Cooper and I had the privilege of fielding a webinar on the subject of data sharing at the invitation of the Long Island Library Resources Council on May 21. The webinar focused on “data communities”—a phrase we coined to describe the social ways in which scientists share and reuse data—and how health sciences librarians can support data communities as they emerge and grow.
Understanding data communities
As we’ve written elsewhere, a data community is a formal or informal network of researchers who share and reuse a particular type of data. Examples of data communities include the scientists who share genomics data via repositories like GenBank, FlyBase, and GISAID, or the scientists who share neuroimaging data via repositories like NITRC, OpenNeuro, and the Donders Repository. A scholar can belong to multiple data communities or no data communities, and can move in and out of a data community as their research interests change.
To flesh out how this definition works in practice, webinar participants tested their knowledge through an interactive quiz: “Is it a Data Community?” Participants were presented with a short description of a data-related initiative and asked to decide whether it was a data community or not. Here are a couple of examples. Make your own guess, then check your answers at the end of this post!
- Is the NIH-figshare repository a data community?
- Is Exposome Explorer a data community?

- Is MetaboLights a data community?

In addition to reinforcing what a data community is, the quiz activity also highlighted how data communities are just one part of a broad ecosystem of individuals, organizations, and initiatives working to advance data sharing.
Why data communities matter in the health sciences
Thinking in terms of data communities can help librarians and other stakeholders support data sharing across institutional and disciplinary boundaries—mirroring how scientists actually do their work. Data communities grow organically from the ground up, as more and more scientists notice the value that their peers derive from sharing and reusing data. But this doesn’t happen automatically. Information professionals can play an important role in supporting data communities as they grow.
Webinar participants learned to recognize emergent data communities—and what types of support they might need—by understanding the data community growth process. Communities start with rudimentary data sharing efforts by small groups of interested researchers, and gradually improve the data sharing process while gaining community participants.
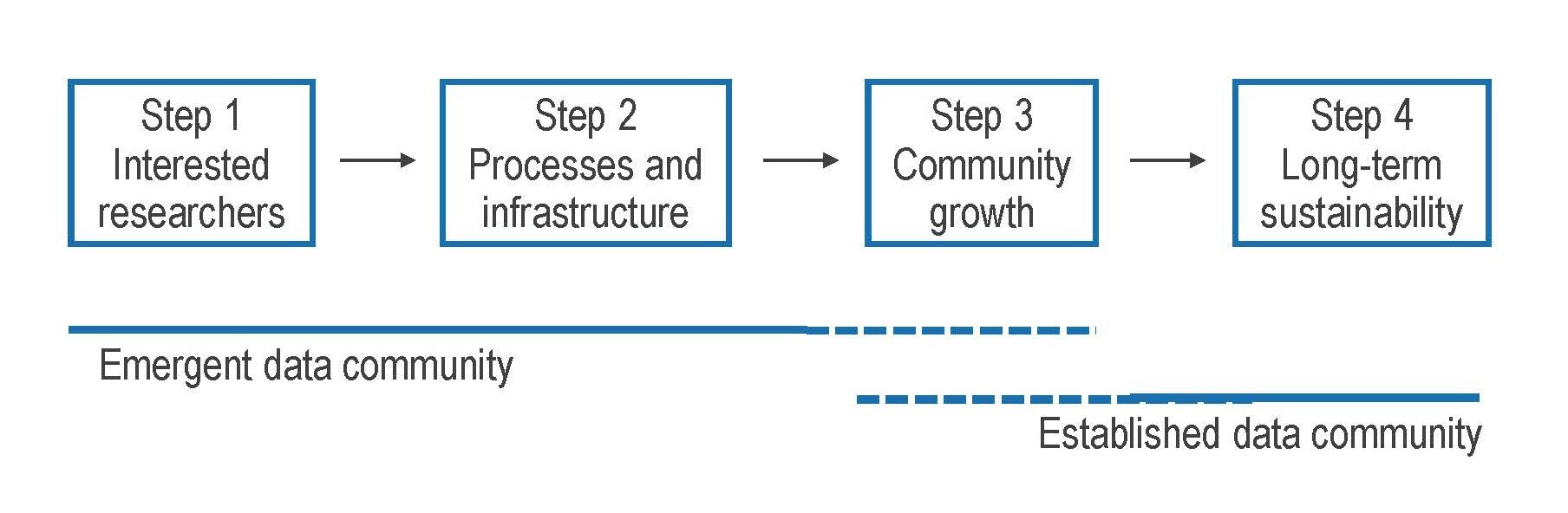 During this process, data communities need help building or identifying appropriate repositories, incorporating metadata and reporting standards into their data sharing practices, making organizational and financial decisions that lead to sustainability, and getting the word out to potential new community members. In the health sciences, data communities have a particularly urgent need for technical assistance with maintaining individual privacy while still maximizing the reusability of datasets. (A timely example of this: the Harvard Dataverse team is currently working on a differential privacy method for anonymizing COVID-19 data.)
During this process, data communities need help building or identifying appropriate repositories, incorporating metadata and reporting standards into their data sharing practices, making organizational and financial decisions that lead to sustainability, and getting the word out to potential new community members. In the health sciences, data communities have a particularly urgent need for technical assistance with maintaining individual privacy while still maximizing the reusability of datasets. (A timely example of this: the Harvard Dataverse team is currently working on a differential privacy method for anonymizing COVID-19 data.)
The webinar concluded with two breakout room discussion sessions, in which participants dug into the practical implications of data communities based on their own knowledge and experiences. One group discussed outreach—how health sciences librarians should identify members of data communities on their own campuses. The other discussed how health sciences librarians should support data communities, given the potential mismatch between librarians’ institutional remits and the fact that data communities usually cross institutional boundaries. Common themes between the two discussion groups included strategies for doing more with less amid COVID-19 budget freeze, and the importance of establishing long-term working relationships to build trust and open dialogue with researchers on campus.
Interested in learning more?
A global data community of health sciences researchers sharing and reusing COVID-19-related data has emerged before our eyes, and with so much lab work paused scientists are taking a fresh look at the potential of research through secondary analysis. These circumstances have made it clear that the key to advancing data sharing lies not in top-down mandates, but in identifying and supporting the efforts of scientists who are motivated to share and reuse data because they recognize that doing so will accelerate research.
Ithaka S+R is currently fielding two collaborative research projects on teaching with data in the social sciences and supporting big data research in partnership with 37 academic libraries. We have also written on a variety of related topics such as data librarianship and the data sharing business landscape. If your institution is interested in hosting a professional development webinar on the topic of data communities or in learning more about our work on research data services, please reach out to Danielle Cooper, manager of collaborations and research, at Danielle.Cooper@ithaka.org.
Answers
- Is the NIH-fighsare repository a data community? No, not on its own—it’s too broad. Instead, according to figshare, it’s intended as “the first step toward evaluating a solution for individual datasets with no clear domain-specific repository.” However, it’s possible to imagine emergent data communities using the NIH-figshare architecture to host their data.
- Is Exposome Explorer a data community? No, it’s a curated data resource that’s made freely available to researchers—which is great, but isn’t a community.
- Is MetaboLights a data community? Yes. It’s also a nice example of a community of scholars drawing on preexisting resources (like controlled vocabularies) to make their data more FAIR, and of journals helping to reinforce community sharing norms by recommending that authors deposit their datasets.